Cassandra: The Database Star Powering Global Scale
In the vast and ever-evolving landscape of modern data management, few technologies shine as brightly or reliably as Apache Cassandra. When we talk about "Cassandra Starr," it's not about a celebrity in the traditional sense, but rather the stellar performance and enduring impact of this distributed database that has become a cornerstone for thousands of companies worldwide. Its ability to handle massive datasets with unparalleled scalability and high availability, all without compromising performance, truly makes it a star in the realm of big data.
This article delves deep into what makes Apache Cassandra such a pivotal technology, exploring its fundamental principles, practical applications, and the robust community that supports its continuous evolution. From its unique NoSQL architecture to its crucial role in powering mission-critical applications, we'll uncover why Cassandra continues to be a top choice for organizations demanding extreme resilience and performance from their data infrastructure.
Table of Contents
- Unveiling Apache Cassandra: A Distributed Database Star
- The Core Strengths of Cassandra: Horizontal Scalability and Beyond
- Getting Started with Cassandra: A Developer's Guide
- Navigating the Official Cassandra Documentation: Your Learning Compass
- Real-World Impact: Cassandra Case Studies and Community Success
- Why Cassandra Shines: E-E-A-T in Distributed Systems
- The Future of Cassandra: Evolution and Innovation
- Conclusion: Embracing the Power of Apache Cassandra
Unveiling Apache Cassandra: A Distributed Database Star
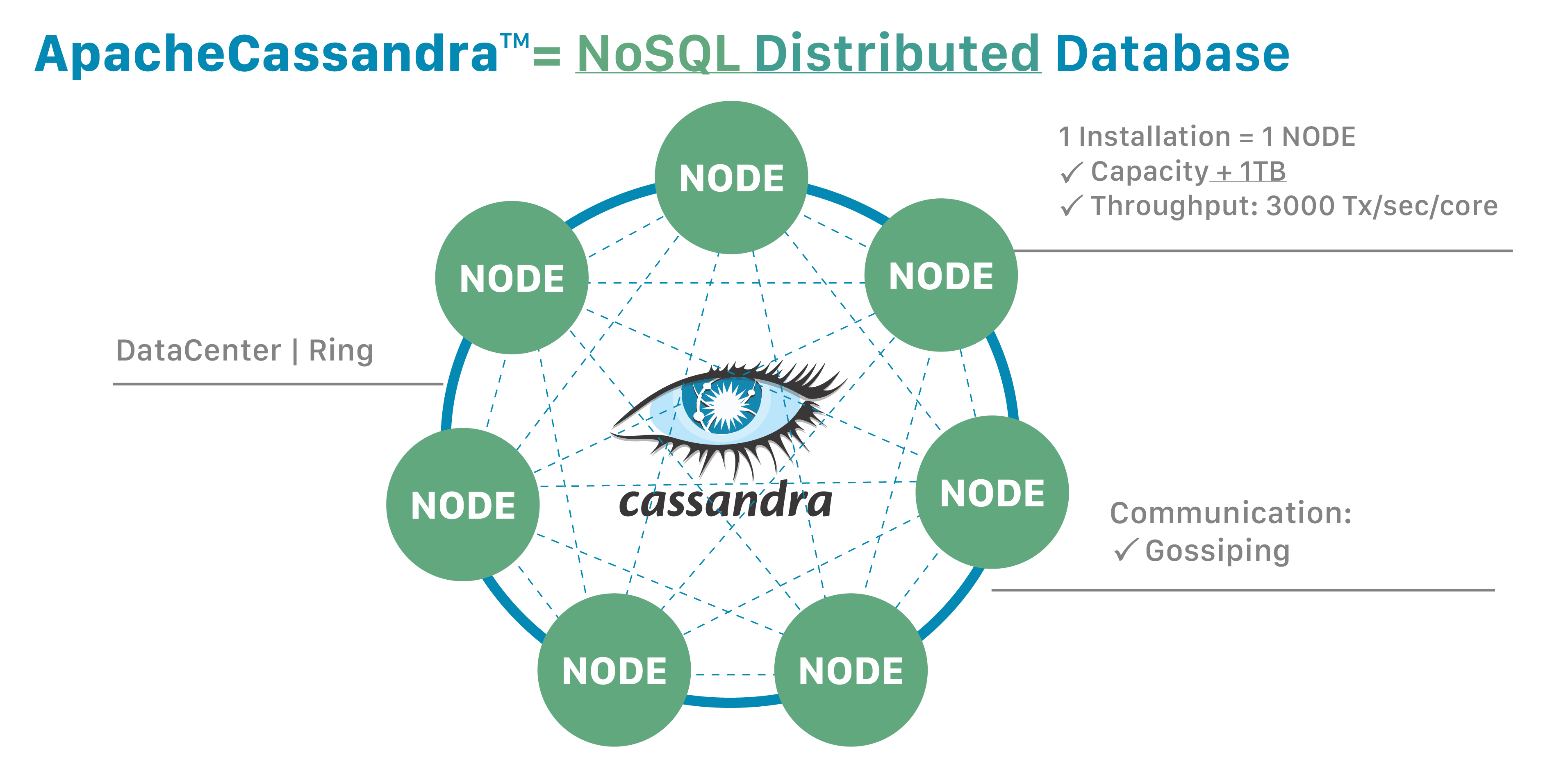
At its heart, Apache Cassandra is an open-source NoSQL distributed database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It was originally developed at Facebook to power its inbox search feature, later open-sourced, and is now maintained by the Apache Software Foundation. The very essence of Cassandra’s design is its ability to scale horizontally, meaning you can add more machines to increase its capacity and performance, rather than upgrading existing ones.
Unlike traditional relational databases (SQL) that rely on a rigid schema and vertical scaling, Cassandra embraces a flexible, column-oriented NoSQL model. This flexibility is crucial for applications that require rapid iteration and can't afford the downtime associated with schema changes in traditional systems. Its masterless architecture ensures that every node in a Cassandra cluster can accept read and write requests, making it incredibly resilient to node failures. This inherent distributed nature is what truly makes Cassandra a star performer in environments where uptime and data accessibility are paramount.
The Core Strengths of Cassandra: Horizontal Scalability and Beyond
When considering a database solution for modern applications, several key attributes stand out, and Apache Cassandra excels in nearly all of them. Counted among its most significant strengths is its unparalleled horizontal scalability. This isn't just a buzzword; it's a fundamental design principle that allows Cassandra clusters to grow seamlessly from a few nodes to hundreds or even thousands, handling petabytes of data and millions of operations per second. This linear scalability means that as your data or user base grows, you can simply add more commodity hardware to meet the demand, without complex re-architecting.
Beyond scalability, Cassandra offers:
- High Availability: With its peer-to-peer architecture, there's no single point of failure. Data is replicated across multiple nodes, ensuring that if one node goes down, the data remains accessible from other replicas. This makes Cassandra incredibly fault-tolerant, a critical feature for any system that cannot afford downtime.
- Performance: Cassandra is optimized for write-heavy workloads, making it ideal for applications that generate a lot of data, such as IoT sensors, real-time analytics, and user activity tracking. Its append-only storage model and log-structured merge-tree (LSM-tree) architecture contribute to its high write throughput. Reads are also highly performant, especially for queries that hit the primary key.
- Decentralized Architecture: Every node in a Cassandra cluster is identical, meaning there are no master or slave nodes. This simplifies management and eliminates bottlenecks. Data is automatically partitioned and distributed across the cluster, and nodes can be added or removed without interrupting service.
- Tunable Consistency: Cassandra allows developers to choose the consistency level for each read and write operation, ranging from "eventual consistency" (fastest, less strict) to "strong consistency" (slower, more strict). This flexibility enables applications to balance performance and data integrity based on their specific needs.
- Durability: Data written to Cassandra is durable, meaning it's persisted to disk and replicated across the cluster, minimizing the risk of data loss even in the event of hardware failures.
These strengths collectively make Cassandra an ideal choice for applications that demand continuous uptime, massive scale, and rapid data ingestion, truly cementing its status as a database star.
Getting Started with Cassandra: A Developer's Guide
For developers eager to harness the power of Apache Cassandra, getting started involves a few key steps, primarily revolving around installation and initial configuration. The official documentation serves as the ultimate guide, but here's a high-level overview to help you begin your journey with this robust database.
Setting Up Your Cassandra Environment
The most common way to install Apache Cassandra on Linux-based systems is by adding its official repository to your system's package manager. For example, to add the Apache repository of Cassandra to /etc/apt/sources.list.d/cassandra.sources.list for the latest 4.1 version, you would typically use a command similar to: echo "deb [signed-by=/usr/share/keyrings/apache-cassandra.gpg] https://downloads.apache.org/cassandra/debian 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list (Note: The exact command might vary slightly based on the specific version and your operating system's package manager, so always refer to the official documentation for the most up-to-date instructions).
Before installing, you'll need to ensure you have Java Development Kit (JDK) installed, as Cassandra is a Java-based application. Once the repository is added and the GPG key imported, you can simply use your package manager (e.g., sudo apt update && sudo apt install cassandra for Debian/Ubuntu) to install the database. For other operating systems like macOS or Windows, alternative installation methods like Docker, Homebrew, or manual tarball extraction are available.
Basic Configuration and First Steps
After installation, the default configuration files for Cassandra are usually located in /etc/cassandra or /opt/cassandra/conf, depending on your installation method. Key files include cassandra.yaml (main configuration), cassandra-env.sh (environment variables), and log4j2.xml (logging configuration). For a single-node setup, the default settings are often sufficient to get started, but for production environments, significant tuning is required.
To start Cassandra, you typically use a command like sudo service cassandra start or cassandra -f for foreground operation. Once started, you can connect to it using the CQLSH (Cassandra Query Language Shell), a command-line client for interacting with Cassandra using CQL. This is where you'll define your keyspaces (similar to databases), tables, and insert/query data. Understanding basic CQL commands is essential for anyone looking to work with Cassandra, marking the beginning of leveraging this powerful database.
Navigating the Official Cassandra Documentation: Your Learning Compass
For anyone looking to truly master Apache Cassandra, the official documentation is an invaluable resource. It serves as the starting page for Apache Cassandra documentation and is meticulously maintained by the Apache Software Foundation and its vibrant community. This comprehensive resource is designed to guide users through every aspect of Cassandra, from foundational concepts to advanced deployment strategies.
The documentation isn't just a static collection of pages; it's a living, evolving body of knowledge. This is the official documentation for Apache Cassandra. If you would like to contribute to this documentation, you are welcome to do so by submitting pull requests on its GitHub repository, reflecting the collaborative spirit of open-source development. This open contribution model ensures that the documentation remains accurate, up-to-date, and reflective of real-world use cases.
Deep Dive into Cassandra Basics: Understanding the Fundamentals
To truly understand Cassandra in more detail, it's crucial to read through the Cassandra basics to learn main concepts and how Cassandra works at a high level. This section typically covers:
- Data Model: Understanding keyspaces, tables, columns, primary keys, clustering keys, and partitions. Cassandra's data model is designed for query-first thinking, meaning you design your tables based on the queries you intend to run, rather than normalizing data as in relational databases.
- Architecture: Delving into how data is distributed across nodes using consistent hashing (the "ring" architecture), replication strategies (SimpleStrategy, NetworkTopologyStrategy), and consistency levels.
- Write and Read Paths: Learning the internal mechanisms of how data is written to commit logs and memtables, flushed to SSTables, and how read requests are processed across multiple replicas.
- Gossip Protocol: How nodes communicate with each other to maintain a consistent view of the cluster state.
- Compaction: The background process that merges SSTables to reclaim disk space and improve read performance.
Grasping these fundamental concepts is essential for designing efficient data models and troubleshooting performance issues in a Cassandra cluster.
Advanced Concepts and Best Practices
Once you have a solid grasp of the basics, to understand Cassandra in more detail, head over to the docs' sections on advanced concepts and best practices. These areas cover:
- Performance Tuning: Optimizing JVM settings, disk I/O, network configuration, and query patterns.
- Security: Implementing authentication, authorization, and encryption for data in transit and at rest.
- Backup and Restore: Strategies for ensuring data recoverability in disaster scenarios.
- Monitoring: Tools and techniques for observing the health and performance of your Cassandra cluster.
- CQL Features: Advanced CQL operations like user-defined types (UDTs), collections, secondary indexes, and materialized views.
- Integration: How Cassandra integrates with other big data tools like Apache Spark, Apache Kafka, and various analytics platforms.
These advanced topics are crucial for anyone planning to deploy and manage Apache Cassandra in a production environment, ensuring its continued stellar performance and reliability.
Real-World Impact: Cassandra Case Studies and Community Success
The true testament to Apache Cassandra's capabilities lies in its widespread adoption by leading companies across various industries. Browse through the case studies to learn how other users in our worldwide community are leveraging Cassandra to solve complex data challenges. These real-world examples highlight Cassandra's versatility and robustness in scenarios demanding extreme scale, high availability, and low-latency data access.
From streaming services handling millions of concurrent users to financial institutions processing countless transactions, Cassandra has proven its mettle. Companies like Apple, Netflix, eBay, Instagram, and Spotify have publicly shared their success stories with Cassandra, often citing its ability to handle massive write volumes, ensure continuous uptime, and scale effortlessly with business growth. For instance, Netflix uses Cassandra to manage billions of user-generated events daily, enabling personalized recommendations and real-time analytics. Apple relies on Cassandra for critical iCloud services, showcasing its trustworthiness for sensitive data at an unprecedented scale.
Browse through the case studies to learn how other users in our worldwide community are pushing the boundaries of what's possible with distributed databases. These stories not only serve as inspiration but also offer valuable insights into best practices, architectural patterns, and lessons learned from deploying Cassandra in diverse, high-stakes environments. The active and supportive global community surrounding Cassandra further amplifies its impact, providing forums, conferences, and open-source contributions that drive innovation and foster knowledge sharing among users worldwide.
Why Cassandra Shines: E-E-A-T in Distributed Systems
In the digital age, where data is the new oil, the principles of E-E-A-T (Expertise, Authoritativeness, Trustworthiness) and YMYL (Your Money or Your Life) are not just for content creators; they are fundamental to the underlying technologies that power our most critical systems. Apache Cassandra embodies these principles, making it a star choice for applications where data integrity, availability, and performance are non-negotiable.
- Expertise: Cassandra was born out of Facebook's need for a highly scalable, fault-tolerant database. Its initial design and ongoing development are driven by a community of world-class engineers and data architects who possess deep expertise in distributed systems. This collective knowledge ensures that Cassandra is built on sound theoretical principles and continually optimized for real-world challenges. The rigorous testing and release cycles of the Apache Software Foundation further validate its technical prowess.
- Authoritativeness: With its adoption by industry giants and its proven track record in mission-critical applications, Cassandra has established itself as an authoritative leader in the NoSQL database space. Its architecture is frequently cited in academic papers and industry benchmarks as a prime example of a robust distributed system. The extensive official documentation and numerous books written about Cassandra further solidify its authoritative standing.
- Trustworthiness: Perhaps the most crucial aspect, Cassandra's design inherently promotes trustworthiness. Its masterless, peer-to-peer architecture with configurable replication ensures that data is highly available and durable, minimizing the risk of data loss or service interruption. For applications dealing with "Your Money or Your Life" data—such as financial transactions, healthcare records, or critical infrastructure management—the reliability and fault tolerance of the underlying database are paramount. While Cassandra itself doesn't directly handle the "Your Money or Your Life" aspect, its ability to provide an extremely stable and consistent data store is what allows applications built upon it to meet strict YMYL requirements for data integrity and continuous operation. Businesses trust Cassandra to protect their most valuable assets: their data and their customers' trust.
The continuous evolution, transparent development process, and strong community support further reinforce Cassandra's E-E-A-T credentials, making it a reliable foundation for any enterprise-grade application.
The Future of Cassandra: Evolution and Innovation
The journey of Apache Cassandra is far from over. The database continues to evolve, driven by the needs of its vast user base and the innovations of its dedicated community. Recent releases have focused on improving performance, simplifying operations, and enhancing security features. For instance, advancements in version 4.0 and beyond have brought significant improvements in areas like:
- Performance and Stability: Continuous efforts to optimize internal mechanisms, reduce latency, and improve overall system stability under heavy loads.
- Developer Experience: Easier installation, improved tooling, and more intuitive ways to interact with the database.
- Observability: Enhanced metrics, logging, and monitoring capabilities to give operators better insights into cluster health and performance.
- Security Enhancements: Stronger encryption options, more granular access controls, and improved auditing features to meet stringent compliance requirements.
- Cloud Native Readiness: Better integration with containerization technologies like Docker and orchestration platforms like Kubernetes, making it easier to deploy and manage Cassandra in cloud environments.
The roadmap for Cassandra consistently reflects a commitment to maintaining its position as a leading distributed database. Future developments are expected to further leverage advancements in hardware, explore new consistency models, and deepen integrations with the broader big data ecosystem. The collaborative nature of its open-source development ensures that Cassandra will continue to adapt to emerging challenges and remain a relevant and powerful solution for data management for years to come.
Conclusion: Embracing the Power of Apache Cassandra
In summary, Apache Cassandra stands as a true star in the constellation of distributed databases. Its foundational strengths in horizontal scalability, high availability, and unwavering performance make it an indispensable tool for thousands of companies grappling with the complexities of modern data volumes. From its origins at Facebook to its current status as a cornerstone of critical applications worldwide, Cassandra has consistently demonstrated its ability to deliver robust and reliable data management solutions.
We've explored its core architecture, practical steps for getting started, the invaluable role of its comprehensive documentation, and the compelling real-world success stories that underscore its impact. Furthermore, Cassandra's adherence to E-E-A-T principles and its suitability for supporting YMYL applications highlight its trustworthiness and authoritative standing in the industry. As data continues to grow exponentially, the future of Cassandra looks bright, with ongoing innovation ensuring its continued relevance.
If you're an organization facing challenges with scaling your data infrastructure, ensuring continuous uptime, or managing high-velocity data streams, exploring Apache Cassandra could be the solution you need. Dive into its official documentation, browse through the inspiring case studies, and consider how this powerful database can transform your data strategy. What are your experiences with distributed databases? Share your thoughts and questions in the comments below, or explore more of our articles on cutting-edge data technologies!

Cassandra: Greek Goddess Who Foretold Cursed Prophecies - Ancient Pages
Apache Cassandra | Apache Cassandra Documentation

Cassandra by Evelyn De Morgan | Obelisk Art History
